联邦进修是一种呆板进修技能,它通过多个独立的会话,每个会话利用本身的数据集来练习一个算法。这种方法与传统的会合式呆板进修技能差异,后者需要将当地数据集归并到一个练习会话中,也与假设当地数据样本是独立同漫衍的要领差异。联邦进修使得多个参加者可以在不共享数据的环境下,构建一个配合的、结实的呆板进修模子,从而办理了数据隐私、数据安详、数据会见权和异构数据会见等要害问题。它的应用涉及了包罗国防、电信、物联网和制药等行业。一个重要的开放问题是何时/是否联邦进修优于汇总数据进修。另一个开放问题涉及设备的可信度和恶意参加者对进修模子的影响。
联邦进修的方针是在多个当地数据集上练习一个配合的呆板进修模子,譬喻深度神经网络。一般道理是在当地数据样本上练习当地模子,并在必然频率下在这些当地节点之间互换参数(譬喻深度神经网络的权重和偏置),以生成一个由所有节点共享的全局模子。联邦进修与漫衍式进修的主要区别在于对当地数据集属性的假设,因为漫衍式进修最初旨在并行化计较本领,而联邦进修最初旨在练习异构数据集。固然漫衍式进修也旨在在多个处事器上练习一个单一模子,但一个常见的潜在假设是当地数据集是独立同漫衍(i.i.d.)而且大抵具有沟通的巨细。而这些假设都不合用于联邦进修;相反,数据集凡是是异构的,而且它们的巨细大概相差几个数量级。另外,参加联邦进修的客户端大概是不行靠的,因为它们更容易呈现妨碍或退出,因为它们凡是依赖于较弱的通信前言(譬喻Wi-Fi)和电池供电系统(譬喻智妙手机和物联网设备),而与之对比,漫衍式进修中的节点凡是是数据中心,它们具有强大的计较本领,而且通过快速网络彼此毗连。
数学上,联邦进修的方针函数如下:
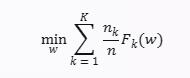
个中K是节点数,wk是节点k看到的模子w的权重,Fk(w)是节点k的当地方针函数,它描写了模子权重如何切合节点k的当地数据集。联邦进修的方针是在所有节点的当地数据集上练习一个配合的模子,换句话说:
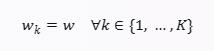
本文将接头联邦进修奇特的特征和挑战,,提供当前要领的遍及概述,并概述一些将来事情的偏向,这些偏向与遍及的研究规模相关。
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。


语法替换")
和rfind()函数:快速查找字串")
 语法")
 语法_链圈子")
、lstrip()和rstrip()语法去")



函数?_链圈子")
函数_链圈子")